- Your LLM requests are relatively static
- Your LLM requests take a long time to execute
- Your LLM requests are expensive
Usage
To enable caching, simply set theX-Pezzo-Cache-Enabled: true header. Here is an example:
- Node.js
- Python
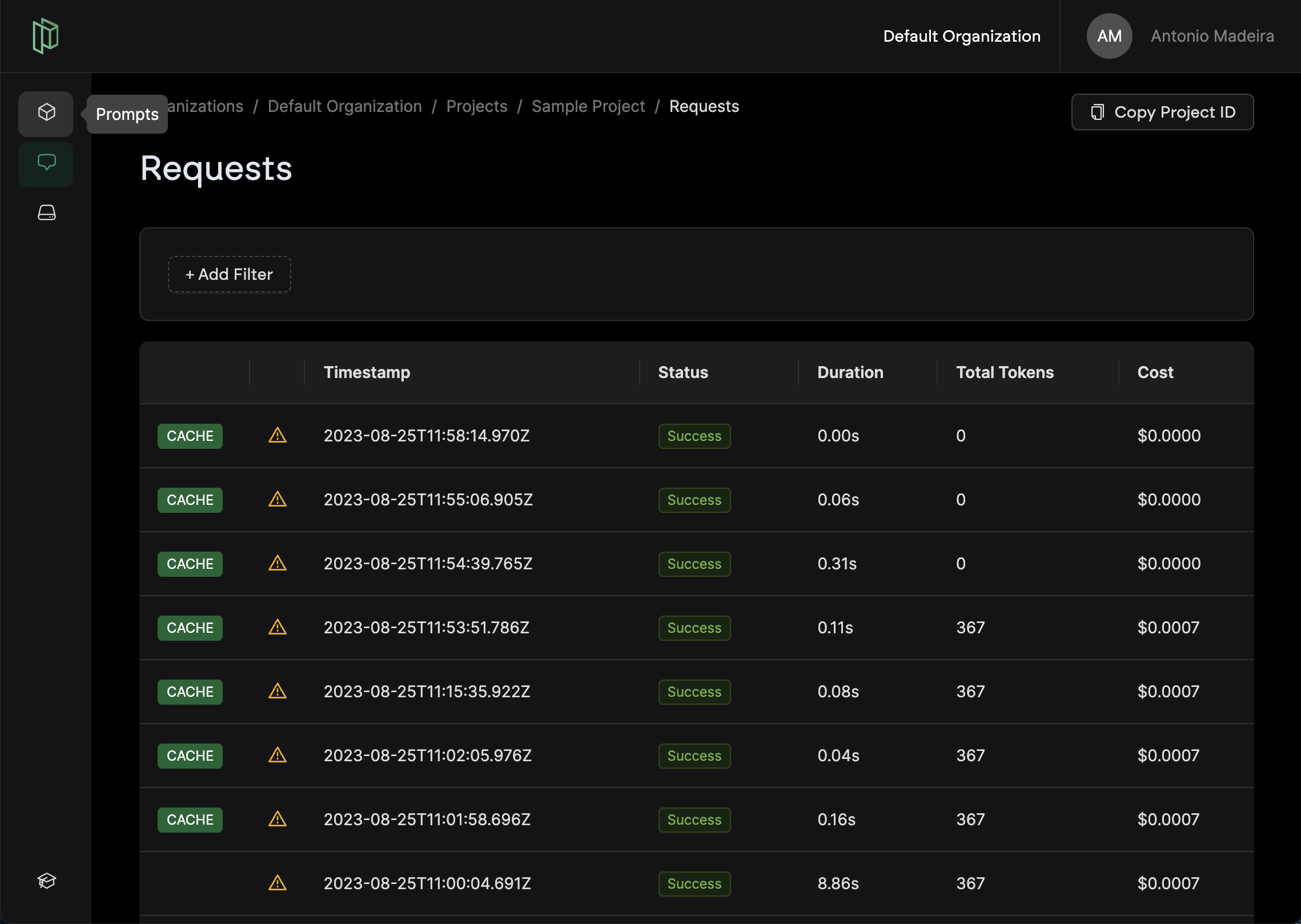
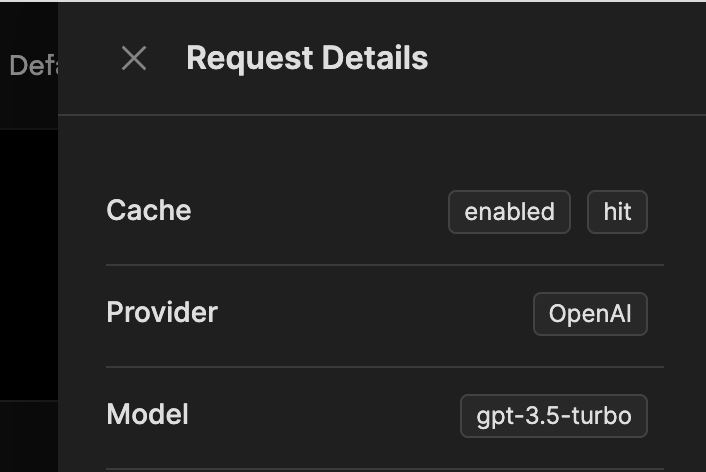
Cached Requests in the Console
Cached requests will will be marked in the Requests tab in the Pezzo Console: